 Elasticsearch: Ingest attachment 插件
Elasticsearch: Ingest attachment 插件
如何从 PPT、XLS 和 PDF 文件中提取数据到 Elasticsearch
👋 欢迎来到 Stackhero 文档!
Stackhero 提供现成的 Elasticsearch 云 解决方案,具有多种优势,包括:
- 由专用私有 VM提供的最佳性能和强大的安全性。
- 支持 HTTPS 加密的可定制域名。
节省时间并简化您的生活:只需 5 分钟即可试用 Stackhero 的 Elasticsearch 云托管 解决方案!
Ingest Attachment 插件解析并提取各种文件格式的元数据和文本,包括 PowerPoint 演示文稿、Excel 文档和 PDF。它利用了强大的文本提取库 Apache Tika。有关支持格式的完整列表,请访问 Tika 的网站。
本指南将帮助您开始使用该插件。
将插件添加到 Elasticsearch
首先,在您的 Stackhero Elasticsearch 配置中启用插件:
- 转到 Stackhero 仪表板中的 Elasticsearch 部分。
- 从可用选项中选择插件
ingest-attachment。
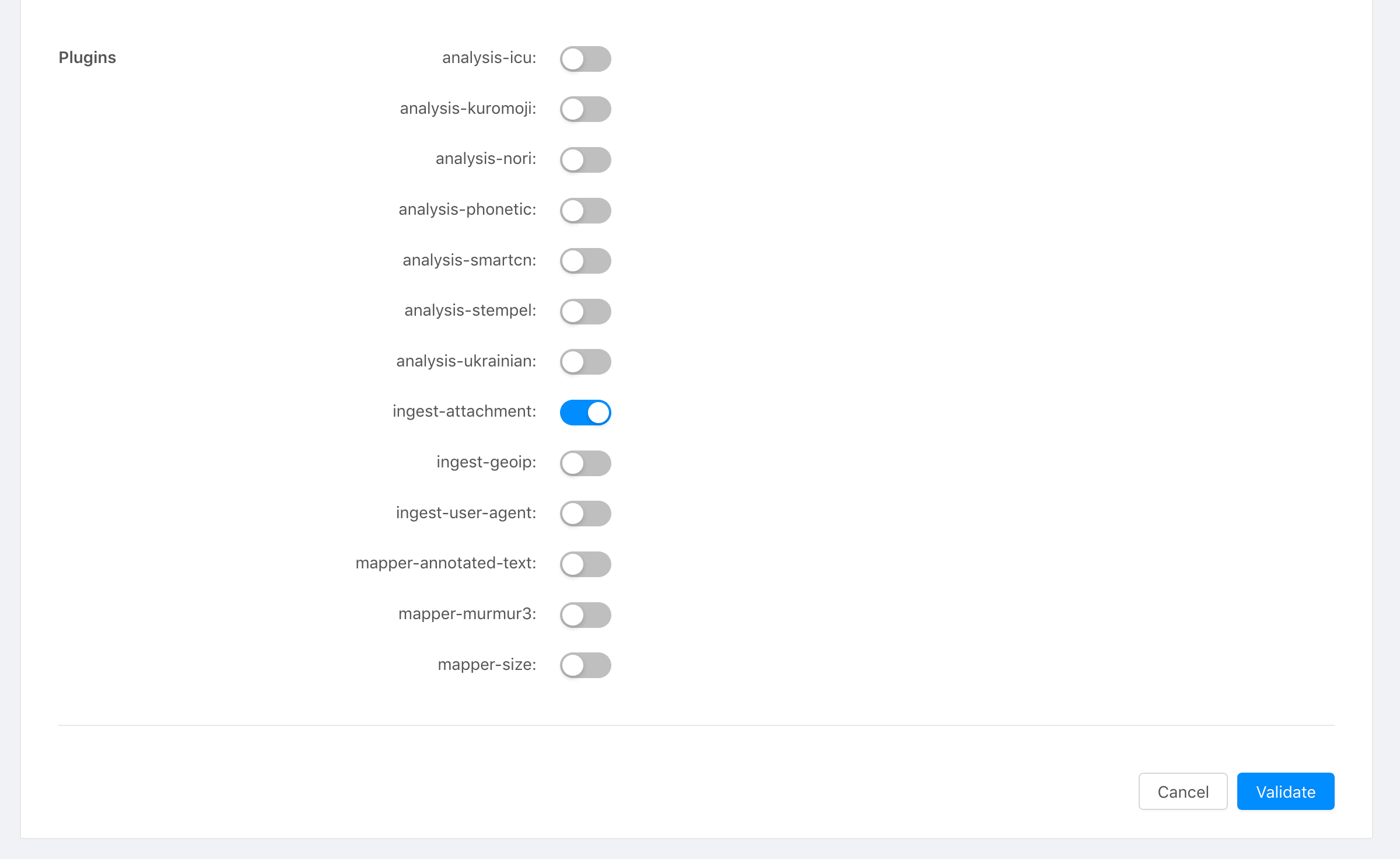 Stackhero 仪表板
Stackhero 仪表板
声明附件管道
接下来,在 Elasticsearch 中声明附件管道。在此示例中,您希望提取的内容存储在字段 data 中:
PUT _ingest/pipeline/attachment
{
"description": "提取附件信息",
"processors": [
{
"attachment": {
"field": "data"
}
}
]
}
我们建议使用 Kibana 中的 "Dev Tools" 来简单地复制/粘贴执行此命令。
 Kibana 开发工具
Kibana 开发工具
添加带有附件的文档
现在您可以索引包含附件的文档。文档应包括一个 data 字段,其中包含以 Base64 编码的文件内容。在此示例中,文档是一个 RTF 文件,包含句子 "This is the content of an RTF file":
PUT my_index/_doc/my_id?pipeline=attachment
{
"data": "e1xydGYxXGFuc2kKVGhpcyBpcyB0aGUgY29udGVudCBvZiBhIFJURiBmaWxlClxwYXIgfQ=="
}
检索带有附件内容的文档
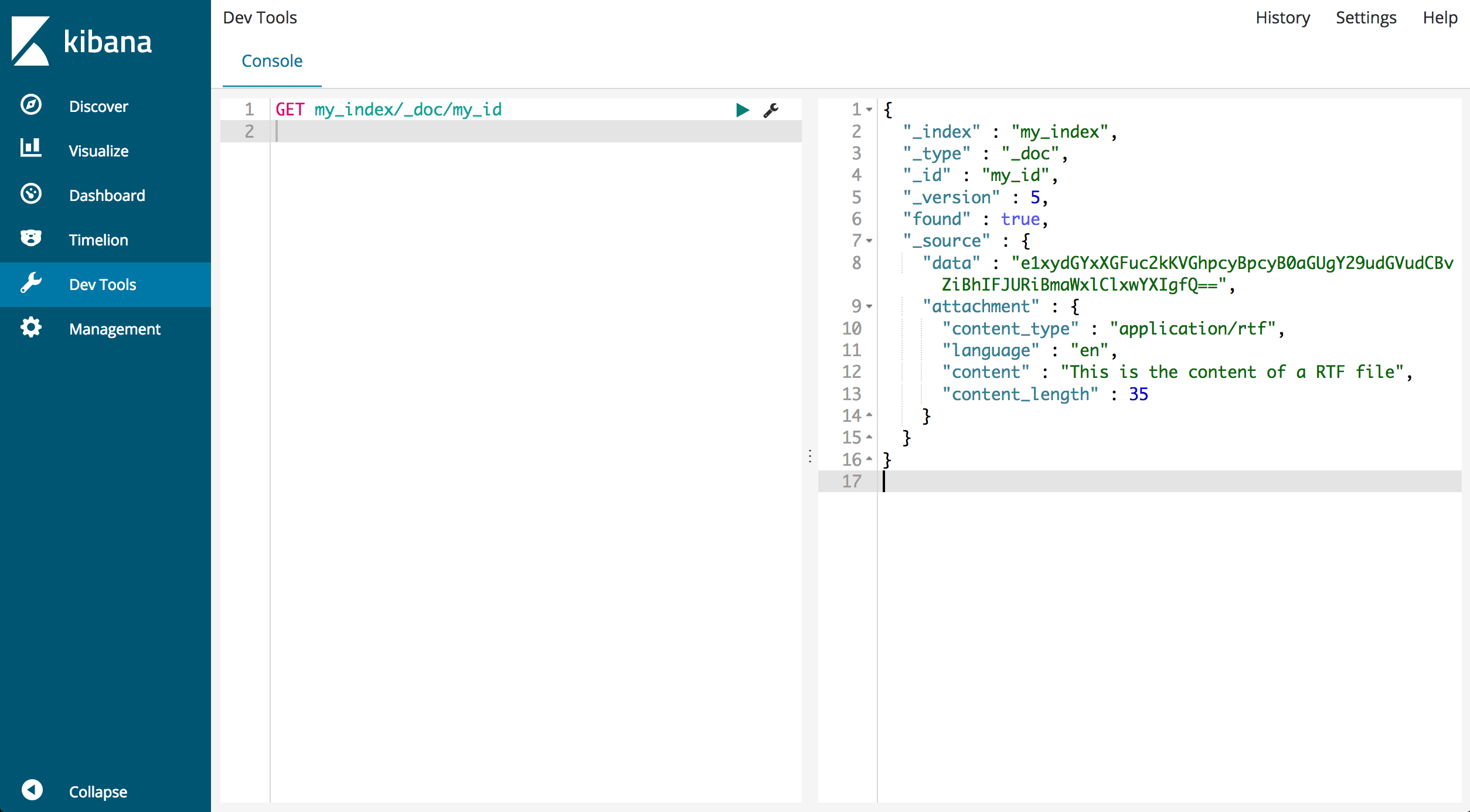
要查看处理后的文档,请使用其 ID 检索它:
GET my_index/_doc/my_id
响应应类似于以下内容:
{
"_index" : "my_index",
"_type" : "_doc",
"_id" : "my_id",
"_version" : 1,
"found" : true,
"_source" : {
"data" : "e1xydGYxXGFuc2kKVGhpcyBpcyB0aGUgY29udGVudCBvZiBhIFJURiBmaWxlClxwYXIgfQ==",
"attachment" : {
"content_type" : "application/rtf",
"language" : "en",
"content" : "This is the content of a RTF file",
"content_length" : 35
}
}
}
请注意,_source 字段现在包括原始 Base64 数据和提取的附件详细信息,如文件类型和内容。
结论
Ingest Attachment 插件是一个强大且用户友好的工具,用于从各种文件格式中提取内容和元数据。它直接与 Elasticsearch 集成,实现无缝的数据摄取。有关更多信息,请参阅 官方文档。