 Elasticsearch: 添付ファイル取り込みプラグイン
Elasticsearch: 添付ファイル取り込みプラグイン
PPT、XLS、PDFファイルからElasticsearchへのデータ抽出方法
👋 Stackheroのドキュメントへようこそ!
Stackheroは、数多くの利点を提供するElasticsearchクラウドソリューションを提供しています。
- プライベートで専用のVMによる最適なパフォーマンスと強力なセキュリティ。
- HTTPS暗号化サポートで保護されたカスタマイズ可能なドメイン名。
時間を節約し、生活を簡素化:StackheroのElasticsearchクラウドホスティングソリューションを試すのに5分しかかかりません!
Ingest Attachmentプラグインは、PowerPointプレゼンテーション、Excelドキュメント、PDFなどのさまざまなファイル形式からメタデータとテキストを解析して抽出します。強力なテキスト抽出ライブラリであるApache Tikaを活用しています。サポートされている形式の詳細なリストについては、Tikaのウェブサイトをご覧ください。
このガイドは、プラグインの使用を開始するのに役立ちます。
Elasticsearchにプラグインを追加する
まず、Stackhero Elasticsearch設定でプラグインを有効にします。
- StackheroダッシュボードのElasticsearchセクションに移動します。
- 利用可能なオプションからプラグイン
ingest-attachmentを選択します。
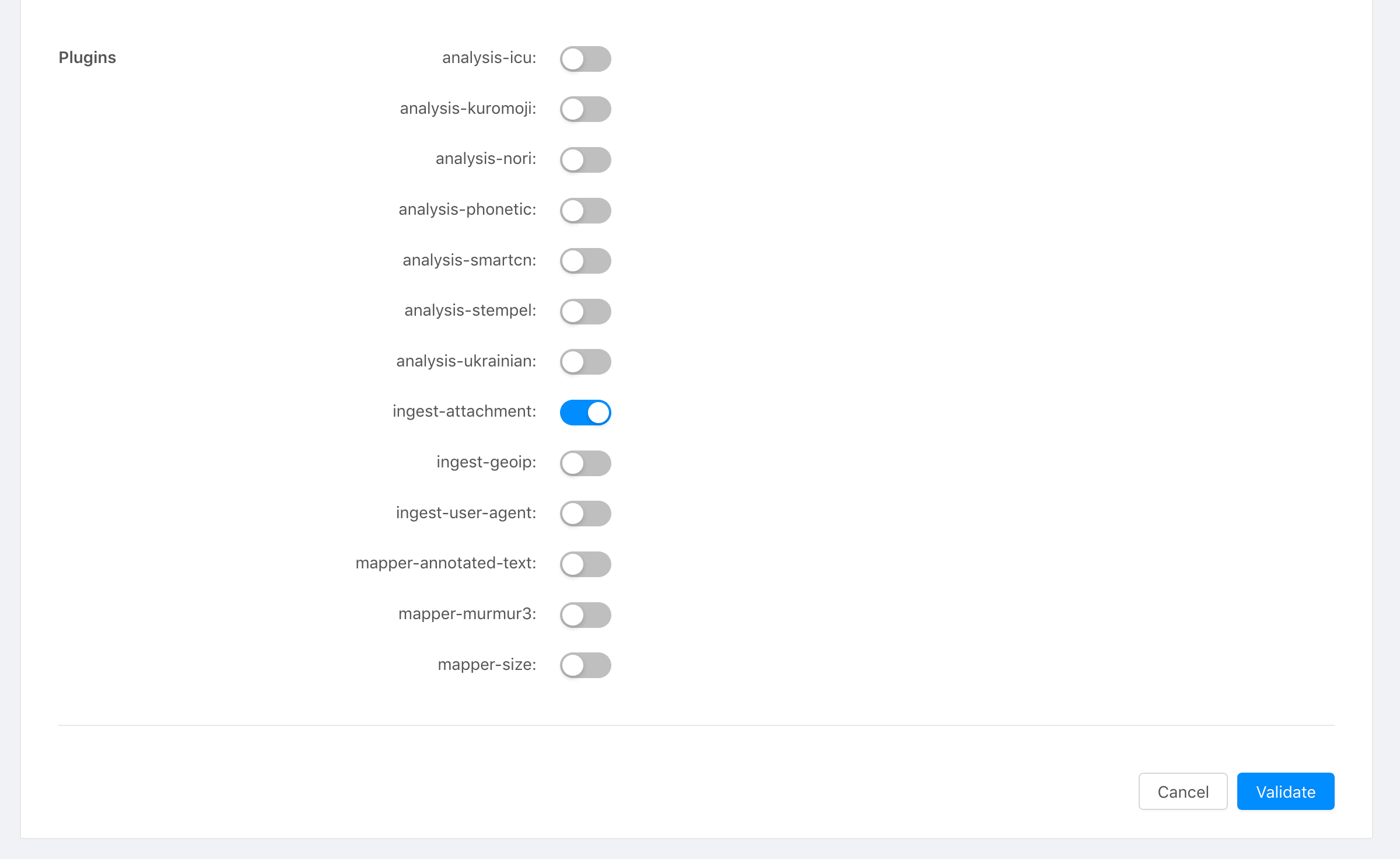 Stackheroダッシュボード
Stackheroダッシュボード
パイプライン添付ファイルを宣言する
次に、Elasticsearchで添付ファイルのパイプラインを宣言します。この例では、抽出したいコンテンツがdataフィールドに格納されています。
PUT _ingest/pipeline/attachment
{
"description": "添付情報を抽出する",
"processors": [
{
"attachment": {
"field": "data"
}
}
]
}
このコマンドを簡単にコピー&ペーストして実行するには、Kibanaの「Dev Tools」を使用することをお勧めします。
 Dev tools Kibana
Dev tools Kibana
添付ファイル付きのドキュメントを追加する
これで、添付ファイルを含むドキュメントをインデックス化できます。ドキュメントには、Base64でエンコードされたファイルコンテンツを保持するdataフィールドを含める必要があります。この例では、ドキュメントは「This is the content of an RTF file」という文を含むRTFファイルです。
PUT my_index/_doc/my_id?pipeline=attachment
{
"data": "e1xydGYxXGFuc2kKVGhpcyBpcyB0aGUgY29udGVudCBvZiBhIFJURiBmaWxlClxwYXIgfQ=="
}
添付コンテンツ付きのドキュメントを取得する
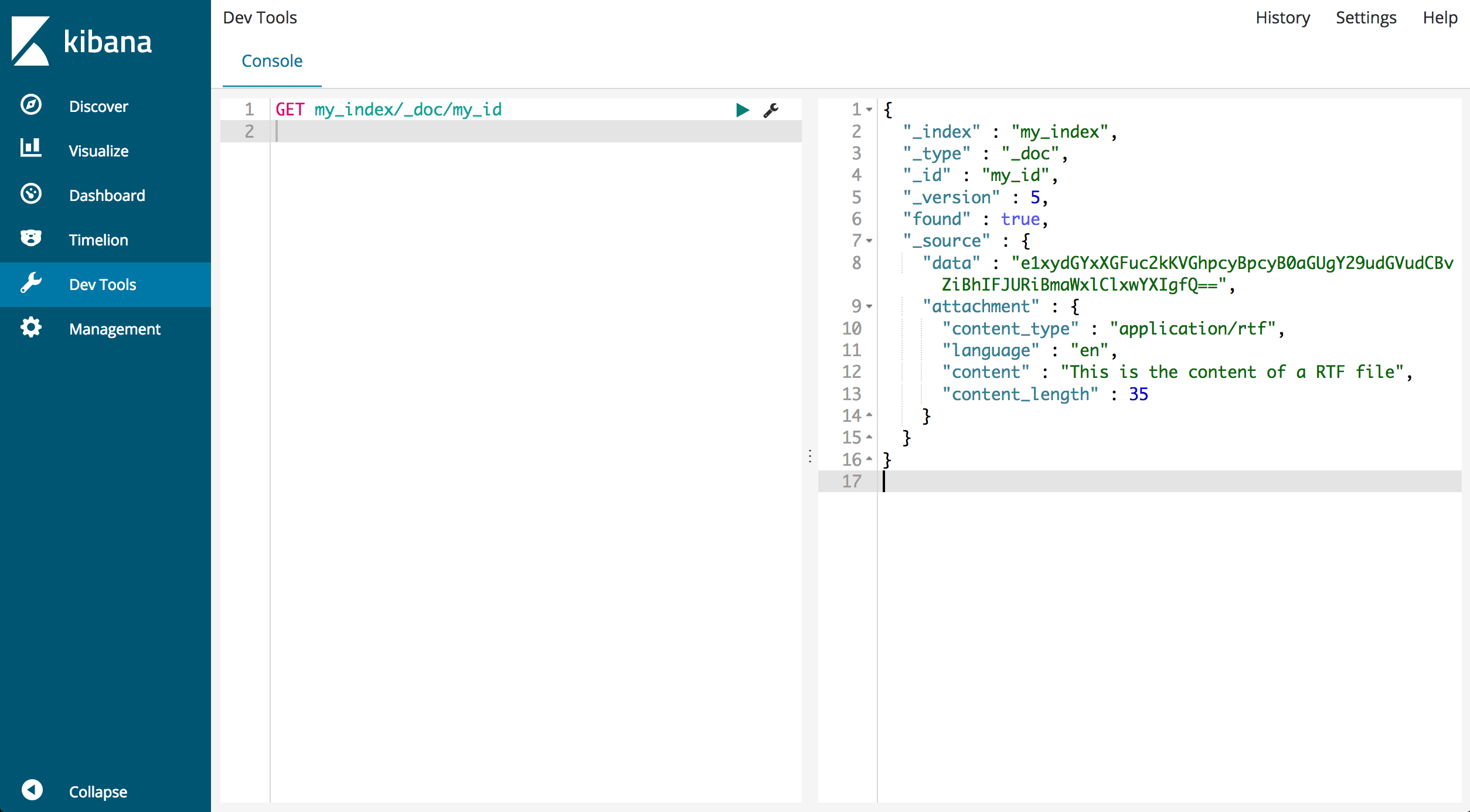
処理されたドキュメントを表示するには、そのIDを使用して取得します。
GET my_index/_doc/my_id
レスポンスは次のようになります。
{
"_index" : "my_index",
"_type" : "_doc",
"_id" : "my_id",
"_version" : 1,
"found" : true,
"_source" : {
"data" : "e1xydGYxXGFuc2kKVGhpcyBpcyB0aGUgY29udGVudCBvZiBhIFJURiBmaWxlClxwYXIgfQ==",
"attachment" : {
"content_type" : "application/rtf",
"language" : "en",
"content" : "This is the content of a RTF file",
"content_length" : 35
}
}
}
_sourceフィールドには、元のBase64データと、ファイルタイプやコンテンツなどの抽出された添付ファイルの詳細が含まれていることに注意してください。
結論
Ingest Attachmentプラグインは、さまざまなファイル形式からコンテンツとメタデータを抽出するための強力で使いやすいツールです。Elasticsearchと直接統合され、シームレスなデータ取り込みを実現します。詳細については、公式ドキュメントをご参照ください。