 Prometheus: 警报
Prometheus: 警报
Prometheus 警报的工作原理及其配置方法
👋 欢迎来到 Stackhero 文档!
Stackhero 提供即用型 Prometheus 云 解决方案,具有多种优势,包括:
- 包含
Alert Manager,可发送警报到Slack、Mattermost、PagerDuty等。- 专用电子邮件服务器发送无限制电子邮件警报。
Blackbox用于探测HTTP、ICMP、TCP等。- 使用在线配置文件编辑器进行简单配置。
- 只需点击即可轻松更新。
- 由专用私有 VM提供的最佳性能和强大安全性。
节省时间并简化生活:只需5 分钟即可试用 Stackhero 的 Prometheus 云托管 解决方案!
Prometheus 警报简介
Prometheus 可以分析您的指标并根据您定义的规则触发警报。使用 Stackhero for Prometheus,警报分两个阶段处理。首先,评估 Prometheus 警报规则,然后由 Alert Manager 接管。
一切都已通过 Stackhero for Prometheus 预安装和配置,因此您只需进行最少的设置,例如添加您的电子邮件地址,即可开始接收警报。
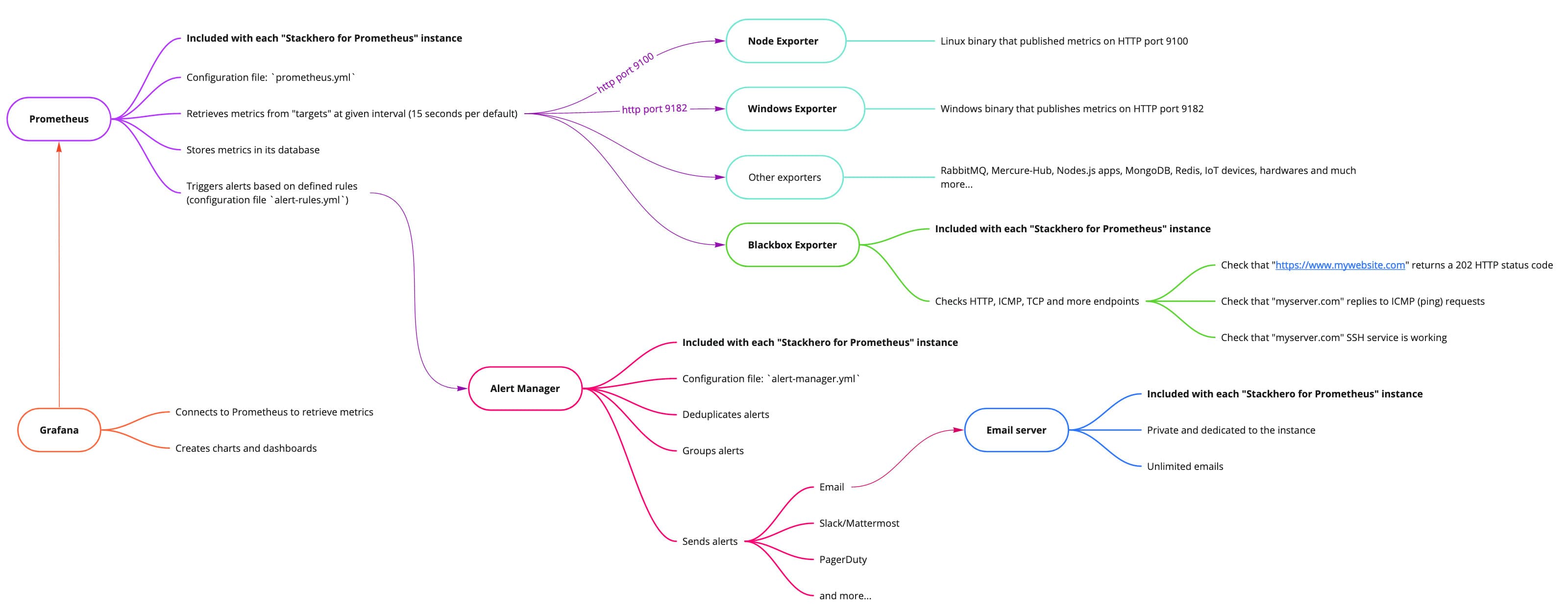 Stackhero for Prometheus 的大图
Stackhero for Prometheus 的大图
Prometheus 警报规则简介
当 Prometheus 检索指标时,它会根据 rules-alert.yml 文件中指定的规则进行评估。这些警报规则定义了触发警报的阈值和时间窗口。
例如,如果磁盘使用率超过 80%,则可以触发警报。此外,还可以设置规则来预测未来的情况,并在估计磁盘空间将在未来 24 小时内完全填满时发送警报。
另一个常见的用例是检测异常行为。例如,如果网络带宽使用突然激增,可以触发警报以帮助检测潜在的分布式拒绝服务 (DDoS) 攻击或数据泄露尝试。
Prometheus 警报规则直接包含在 Prometheus 服务器中。
Alert Manager 简介
Alert Manager 接收由 Prometheus 警报规则触发的警报。它去重警报,进行分组,然后通过各种通知渠道(如电子邮件、Slack、Mattermost、PagerDuty 等)转发。其配置文件为 alert-manager.yml。
例如,如果服务器出现缓慢,Prometheus 警报规则可能会触发针对负载增加和 CPU 使用率的单独警报。Alert Manager 接收这些警报,将它们分组,因为它们与同一服务器相关,并根据您的配置向适当的接收者或团队发送单个合并通知。
如果缓慢持续,Prometheus 将继续发送警报,但 Alert Manager 将在指定时间内抑制重复消息,以防止您的团队被冗余警报淹没。
如果需要,您还可以静音或完全抑制警报。一旦解决了根本问题,将发送恢复消息以通知您的团队。
此示例说明了一个常见场景,但您可以完全自定义设置以满足您的特定需求。
警告
Alert Manager默认不包含在 Prometheus 中。 为了节省您的时间并简化流程,我们已在 Stackhero for Prometheus 中集成并配置了Alert Manager,因此您只需几分钟即可发送警报,几乎不需要任何努力。
配置 Prometheus 警报规则
您可以通过编辑 rules-alert.yml 文件来调整 Prometheus 警报规则。为此,请访问您的 Stackhero 仪表板,选择您的 Prometheus 服务,然后点击“Prometheus 警报规则配置”。
我们已经在您的 Stackhero for Prometheus 实例中添加了一些默认警报规则,因此通常不需要修改 rules-alert.yml 文件,除非需要自定义。
以下是一个示例,当磁盘使用率超过 90% 时触发警报:
- alert: "HostOutOfDiskSpace"
expr: (node_filesystem_avail_bytes * 100) / node_filesystem_size_bytes < 10 and ON (instance, device, mountpoint) node_filesystem_readonly == 0
for: 2m
labels:
severity: "warning"
annotations:
summary: "Host out of disk space (instance {{ $labels.instance }})"
description: "Disk is almost full (< 10% left)"
value: "{{ $value }}"
这是另一个示例,预测未来 24 小时内磁盘空间可能饱和:
- alert: "HostDiskWillFillIn24Hours"
expr: (node_filesystem_avail_bytes * 100) / node_filesystem_size_bytes < 10 and ON (instance, device, mountpoint) predict_linear(node_filesystem_avail_bytes{fstype!~"tmpfs"}[1h], 24 * 3600) < 0 and ON (instance, device, mountpoint) node_filesystem_readonly == 0
for: 2m
labels:
severity: "warning"
annotations:
summary: "Host disk will fill in 24 hours (instance {{ $labels.instance }})"
description: "Filesystem is predicted to run out of space within the next 24 hours at the current write rate"
value: "{{ $value }}"
您可以在 Awesome Prometheus Alerts 网站上找到更多警报规则示例。
配置 Alert Manager
要配置 Alert Manager,请编辑 alert-manager.yml 文件。在您的 Stackhero 仪表板中,选择您的 Prometheus 服务,然后点击“Alert Manager 配置”。
下面我们介绍基础知识。有关更多详细信息,请参阅官方文档。
配置 Alert Manager:接收者
第一步是配置 receivers。每个 receiver 是一组通知集成(如电子邮件、Slack 等),由唯一的 name 标识。
例如,您可以创建一个名为 "critical_alert" 的接收者,用于由严重警报触发的通知。或者,您可以创建一个类似 "devops_team" 的接收者,将警报定向到您的 DevOps 团队。
仅将
receiver名称设置为 "critical_alert" 不会发送警报。警报与接收者之间的关联是在下面描述的routes配置中完成的。
定义接收者后,您需要设置相应的通知集成。这些可能包括电子邮件、Slack/Mattermost 通知、PagerDuty、Opsgenie、Webhook 等。
以下是一个名为 "critical_alert" 的 receiver 示例,它向两个用户发送电子邮件,并向 #alerts 频道发送 Slack 消息:
receivers:
- name: "critical_alert"
# 通过电子邮件发送严重警报
email_configs:
- send_resolved: true
to: "[email protected]"
# 向 Slack 或 Mattermost 发送严重警报
slack_configs:
- send_resolved: true
api_url: "<your Slack or Mattermost API URL>"
channel: "#alerts"
title: "{{ range .Alerts }}{{ .Annotations.summary }}\n{{ end }}"
text: "{{ range .Alerts }}{{ .Annotations.description }}\n{{ end }}"
您可以定义多个接收者来处理不同类型的警报。例如,您可能有一个用于严重警报,另一个用于错误警报,还有一个用于其他类型的警报。
Stackhero for Prometheus 实例包括一个专用和私有的电子邮件服务器,允许您无限制地发送电子邮件警报,无需额外费用。
配置 Alert Manager:路由
配置完接收者后,您需要设置 routes。路由告诉 Alert Manager 如何处理来自 Prometheus 的传入警报以及将其发送到哪里(通常是您预配置的接收者之一)。
以下是一个基本示例,将严重性为 "critical" 的警报定向到名为 "critical_alert" 的接收者:
route:
routes:
- match:
severity: "critical"
receiver: "critical_alert"
我们已在提供的 Stackhero for Prometheus 实例的
alert-manager.yml文件中预配置了一些路由。要开始接收警报,只需使用您的通知详细信息更新email_configs和/或slack_configs部分。