 Prometheus: アラート
Prometheus: アラート
Prometheusアラートの仕組みと設定方法
👋 Stackheroのドキュメントへようこそ!
Stackheroは、数多くの利点を提供するPrometheusクラウドソリューションを提供しています。主な利点は以下の通りです:
Alert Managerが含まれており、Slack、Mattermost、PagerDutyなどにアラートを送信できます。- 無制限のメールアラートを送信できる専用メールサーバー。
BlackboxでHTTP、ICMP、TCPなどをプローブ。- オンライン設定ファイルエディタによる簡単な設定。
- ワンクリックでの手間いらずの更新。
- プライベートで専用のVMによる最適なパフォーマンスと強固なセキュリティ。
時間を節約し、生活を簡素化:StackheroのPrometheusクラウドホスティングソリューションを試すのに5分しかかかりません!
Prometheusアラートの紹介
Prometheusは、定義したルールに基づいてメトリクスを分析し、アラートをトリガーできます。Stackhero for Prometheusでは、アラートは2段階で処理されます。まず、Prometheusのアラートルールが評価され、その後Alert Managerが引き継ぎます。
すべてがStackhero for Prometheusで事前にインストールおよび設定されているため、メールアドレスを追加するなどの最小限の設定を行うだけで、アラートを受信し始めることができます。
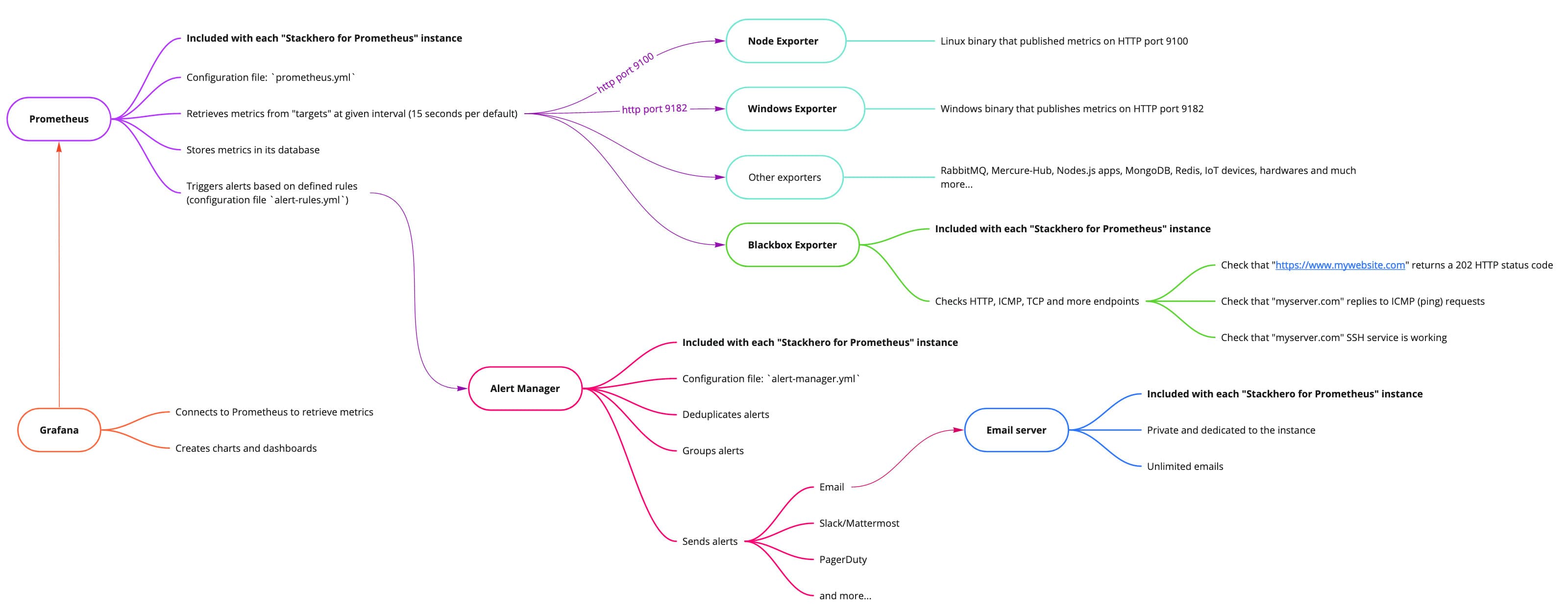 Stackhero for Prometheusの全体像
Stackhero for Prometheusの全体像
Prometheusアラートルールの紹介
Prometheusがメトリクスを取得すると、rules-alert.ymlファイルに指定されたルールに基づいて評価されます。これらのアラートルールは、収集されたメトリクスに基づいてアラートをトリガーするためのしきい値と時間枠を定義します。
例えば、ディスク使用率が80%を超えた場合にアラートがトリガーされることがあります。さらに、将来の状況を予測し、24時間以内にディスクスペースが完全に埋まると推定される場合にアラートを送信するようにルールを設定できます。
もう一つの一般的な使用例は、異常な動作を検出することです。例えば、ネットワーク帯域幅の使用が急増した場合、分散型サービス拒否(DDoS)攻撃やデータ流出の試みを検出するためにアラートがトリガーされることがあります。
Prometheusのアラートルールは、直接Prometheusサーバーに含まれています。
Alert Managerの紹介
Alert Managerは、Prometheusのアラートルールによってトリガーされたアラートを受信します。アラートを重複排除し、グループ化し、メール、Slack、Mattermost、PagerDutyなどのさまざまな通知チャネルを通じて転送します。設定ファイルはalert-manager.ymlです。
例えば、サーバーの遅延が発生した場合、Prometheusのアラートルールは負荷増加とCPU使用率のために個別のアラートをトリガーするかもしれません。Alert Managerはこれらのアラートを受信し、同じサーバーに関連するためグループ化し、設定に基づいて適切な受信者またはチームに統合された通知を送信します。
遅延が続く場合、Prometheusはアラートを送り続けますが、Alert Managerは指定された期間、重複するメッセージを抑制し、チームに冗長なアラートを送信しないようにします。
必要に応じてアラートをサイレンスまたは完全に抑制することもできます。根本的な問題が解決されると、復旧メッセージが送信され、チームに通知されます。
この例は一般的なシナリオを示していますが、特定の要件に合わせて設定を完全にカスタマイズできます。
警告
Alert Managerは、デフォルトではPrometheusに含まれていません。 時間を節約し、プロセスを簡素化するために、Stackhero for PrometheusにAlert Managerを統合および設定しましたので、最小限の労力で数分でアラートを送信できます。
Prometheusアラートルールの設定
Prometheusアラートルールは、rules-alert.ymlファイルを編集することで調整できます。これを行うには、Stackheroダッシュボードにアクセスし、Prometheusサービスを選択し、「Prometheusアラートルールの設定」をクリックします。
Stackhero for Prometheusインスタンスには、すでにいくつかのデフォルトのアラートルールが追加されているため、カスタマイズが必要でない限り、通常はrules-alert.ymlファイルを変更する必要はありません。
以下は、ディスク使用率が90%を超えた場合にトリガーされるアラートの例です:
- alert: "HostOutOfDiskSpace"
expr: (node_filesystem_avail_bytes * 100) / node_filesystem_size_bytes < 10 and ON (instance, device, mountpoint) node_filesystem_readonly == 0
for: 2m
labels:
severity: "warning"
annotations:
summary: "Host out of disk space (instance {{ $labels.instance }})"
description: "Disk is almost full (< 10% left)"
value: "{{ $value }}"
次は、24時間以内にディスクスペースの飽和を予測する例です:
- alert: "HostDiskWillFillIn24Hours"
expr: (node_filesystem_avail_bytes * 100) / node_filesystem_size_bytes < 10 and ON (instance, device, mountpoint) predict_linear(node_filesystem_avail_bytes{fstype!~"tmpfs"}[1h], 24 * 3600) < 0 and ON (instance, device, mountpoint) node_filesystem_readonly == 0
for: 2m
labels:
severity: "warning"
annotations:
summary: "Host disk will fill in 24 hours (instance {{ $labels.instance }})"
description: "Filesystem is predicted to run out of space within the next 24 hours at the current write rate"
value: "{{ $value }}"
Awesome Prometheus Alertsウェブサイトで、さらに多くのアラートルールの例を見つけることができます。
Alert Managerの設定
Alert Managerを設定するには、alert-manager.ymlファイルを編集します。StackheroダッシュボードでPrometheusサービスを選択し、「Alert Managerの設定」をクリックします。
以下に基本を示します。詳細については、公式ドキュメントを参照してください。
Alert Managerの設定:レシーバー
最初のステップは、receiversを設定することです。各receiverは、ユニークなnameで識別される通知統合(メール、Slackなど)のセットです。
例えば、重大なアラートによってトリガーされる通知のために「critical_alert」という名前のレシーバーを作成することができます。あるいは、DevOpsチームにアラートを送るために「devops_team」というレシーバーを作成することもできます。
receiver名を「critical_alert」に設定するだけではアラートは送信されません。アラートとレシーバーの関連付けは、以下で説明するroutes設定で行われます。
レシーバーが定義されたら、対応する通知統合を設定する必要があります。これには、メール、Slack/Mattermost通知、PagerDuty、Opsgenie、Webhookなどが含まれる可能性があります。
以下は、2人のユーザーにメールを送り、#alertsチャンネルにSlackメッセージを送信する「critical_alert」という名前のreceiverの例です:
receivers:
- name: "critical_alert"
# 重大なアラートをメールで送信
email_configs:
- send_resolved: true
to: "[email protected]"
# 重大なアラートをSlackまたはMattermostに送信
slack_configs:
- send_resolved: true
api_url: "<your Slack or Mattermost API URL>"
channel: "#alerts"
title: "{{ range .Alerts }}{{ .Annotations.summary }}\n{{ end }}"
text: "{{ range .Alerts }}{{ .Annotations.description }}\n{{ end }}"
異なる種類のアラートを処理するために複数のレシーバーを定義できます。例えば、重大なアラート用、エラーアラート用、その他のアラート用のレシーバーを持つことができます。
Stackhero for Prometheusのインスタンスには、無制限のメールアラートを追加費用なしで送信できる専用のプライベートメールサーバーが含まれています。
Alert Managerの設定:ルート
レシーバーを設定した後、routesを設定する必要があります。ルートは、Alert ManagerにPrometheusからのアラートをどのように処理し、どこに送信するか(通常は事前に設定されたレシーバーの1つ)を指示します。
以下は、「critical」という重大度のアラートを「critical_alert」という名前のレシーバーに送信する基本的な例です:
route:
routes:
- match:
severity: "critical"
receiver: "critical_alert"
Stackhero for Prometheusインスタンスに提供される
alert-manager.ymlファイルには、いくつかのルートが事前に設定されています。アラートを受信し始めるには、email_configsおよび/またはslack_configsセクションを通知の詳細で更新するだけです。